Being a massive geek for longer than I can remember, I’m one of those people who has multiple internet connections at home. Thankfully, I also run the ISP who delivers these internet connections which affords me quite a lot of flexibility in how the service is delivered.
I have used pfSense for a number of years, recently acquiring a dedicated Netgate SG-3100 appliance. In the past, I’ve had a Cisco 887VA do the PPPoE and route IP addresses to my pfSense appliance. This has worked well but I noticed recently that the 887VA wasn’t able to route IPv6 as quickly as IPv4, so I decided to take the one (now two) VDSL modems straight into the Netgate and utilise PPPoE there.
Ordinarily, I’ve done simple load balancing in pfSense, using gateway groups and firewall rules to route traffic accordingly. This works well for IPv4 but doesn’t work well for IPv6 and has a couple of other small annoyances such as breaking sites which utilise sessions and so on. Easily fixed by pinning certain types of traffic to one particular gateway group with a primary connection and a failover connection. However, I thought I could go one better and wanted to achieve the following:
- All traffic in / out should utilise one set of IPv4 or IPv6 addresses, rather than two sets as is standard in a normal load balancing scenario;
- Traffic should be split as equally as possible across both FTTC connections (they sync within 1M of eachother);
- The solution should be robust and be able to tolerate some element of failure. e.g. One connection goes down in the middle of the night due to carrier maintenance;
- The solution should be able to recover gracefully without intervention from myself if connections disconnect and reconnect;
- No additional latency or significant loss in throughput should be observed. Neither should any packet loss be introduced.
The Solution
This is where Linux comes in. Specifically, Debian 10.
I started by firing up a Debian 10 virtual machine on my ESXi host, creating some new VLANs and configuring some tagged/untagged ports on my switch. This was to allow each FTTC modem to sit on its own VLAN and be safely passed through to ESXi where I could create new port groups for each respective VLAN. It’s important to note at this point that in order to utilise an MTU of 1500 on my ppp interfaces in Linux, I needed to ensure jumbo frames was enabled on the ports on my switch that the ESXi host and modems were plugged into. I then made sure that jumbo frames were also enabled on my vSwitch in ESXi.
Finally, I was ready to start testing in Debian. The client side and remote side routers need to be configured to route traffic for your IP addresses down both lines at the same time. In my case, I’m lucky enough to be able to control the ISP side of the routing and I use Firebrick routers which allow bonding of this nature out of the box. I started by configuring the Firebricks to route traffic destined for my IPv4 and IPv6 addresses down both connections with the same preference.
For the client-side, I started out using ECMP (Equal-Cost Multi-Path) routing. ECMP is built-in to the Linux kernel and has improved significantly over the last few years. This solution didn’t end up working out as I had hoped as I saw inconsistencies with traffic across both lines and upload traffic only seemed to be using one line at a time.
This is where TEQL comes in. On the face of it, TEQL looks really easy to implement which made me worry about how well it’d actually work (I guess I’m used to technology filling me with rage). Turns out, it works pretty well. All you need is your standard PPP configuration in /etc/ppp/peers/ where I have two almost identical files for each connection (PPP logins are different). It looks a little something like this:
user <pppoe_username> plugin rp-pppoe.so ens224 noipdefault nodefaultroute hide-password lcp-echo-interval 1 lcp-echo-failure 10 noauth persist maxfail 0 mtu 1500 noaccomp default-asyncmap +ipv6 ipv6cp-use-ipaddr
In addition, I have a bit of config in /etc/network/interfaces to bring up the interfaces at boot time. The MTU of 1508 on the NICs themselves is to allow the additional overheads of PPPoE and an MTU of 1500 on the PPP interface when it comes up. This is why I enabled jumbo frames on my other network equipment further up this page.
auto dsl-provider
iface dsl-provider inet ppp
pre-up /sbin/ifconfig ens224 mtu 1508 up
provider unchained
mtu 1508
auto dsl-provider
iface dsl-provider inet ppp
pre-up /sbin/ifconfig ens256 mtu 1508 up
provider unchained-ttb
mtu 1508
Now all I needed was the magic of TEQL. Initially, this didn’t want to work, then I realised that I needed to load a kernel module before doing the configuration. Simply adding ‘sch_teql’ to my /etc/modules file ensured this was loaded at boot time. And if you want to load the module without rebooting, simply run ‘modprobe sch_teql’ at the command line.
Finally, all that was left to do was creating a virtual device named ‘teql0’, bringing it up, assigning my PPP devices to it and ensuring the default routes for IPv4 and IPv6 utilised the teql0 device for its default gateway. This was achieved with a small script that sits in /etc/ppp/ip-up.d/routing and gets automatically run when the PPP interfaces get brought up.
#!/bin/bash tc qdisc add dev ppp0 root teql0 tc qdisc add dev ppp1 root teql0 ip link set teql0 up ip route replace default scope global dev teql0 ip -6 route replace default scope global dev teql0
To see this work in all its glory, I just had to look at the local routing table using ‘ip route’ and ‘ip -6 route’ (some link-local addresses have been redacted from the output below).
# ip route default dev teql0 # ip -6 route default dev teql0 metric 1024 pref medium
You can also check that tc (traffic control) is seeing the teql0 interface correctly with the 2 PPP interfaces assigned to it:
# tc -s qdisc qdisc teql0 8032: dev ppp1 root refcnt 2 Sent 228 bytes 3 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0 qdisc teql0 8039: dev ppp0 root refcnt 2 Sent 228 bytes 3 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0
It’s worth noting that I route a /29 IPv4 prefix and a /48 IPv6 prefix down to me so have an additional interface on the system with IP’s configured from those subnets and routed further to my pfSense box for actual use.
Conclusion
So, what does this solution look like on a speedtest with one connection synced at 60M down and the other at 59M down and upload speeds around the 14M and 12M marks, respectively.

By default, speedtest.net uses multi-threaded connections. I wanted to see what single-threaded performance was like. So kicked off a test download from a Hetzner speedtest site.
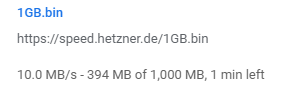
I’ve seen this hit around 12-14MB/s depending on what else is going on, so that is pretty impressive.
During my searches about teql, I read that TCP reordering could be a problem but I didn’t see any real evidence of this in my case when analysing a tcpdump on the router. Thankfully, all other applications, VoIP, gaming, etc have been spot-on and I haven’t noticed any negative performance implications.
Finally, if you want to read more about tc (traffic control) and teql (true link equaliser). I would suggest heading over to https://www.tldp.org/HOWTO/Adv-Routing-HOWTO/lartc.loadshare.html and https://en.wikipedia.org/wiki/Tc_(Linux).